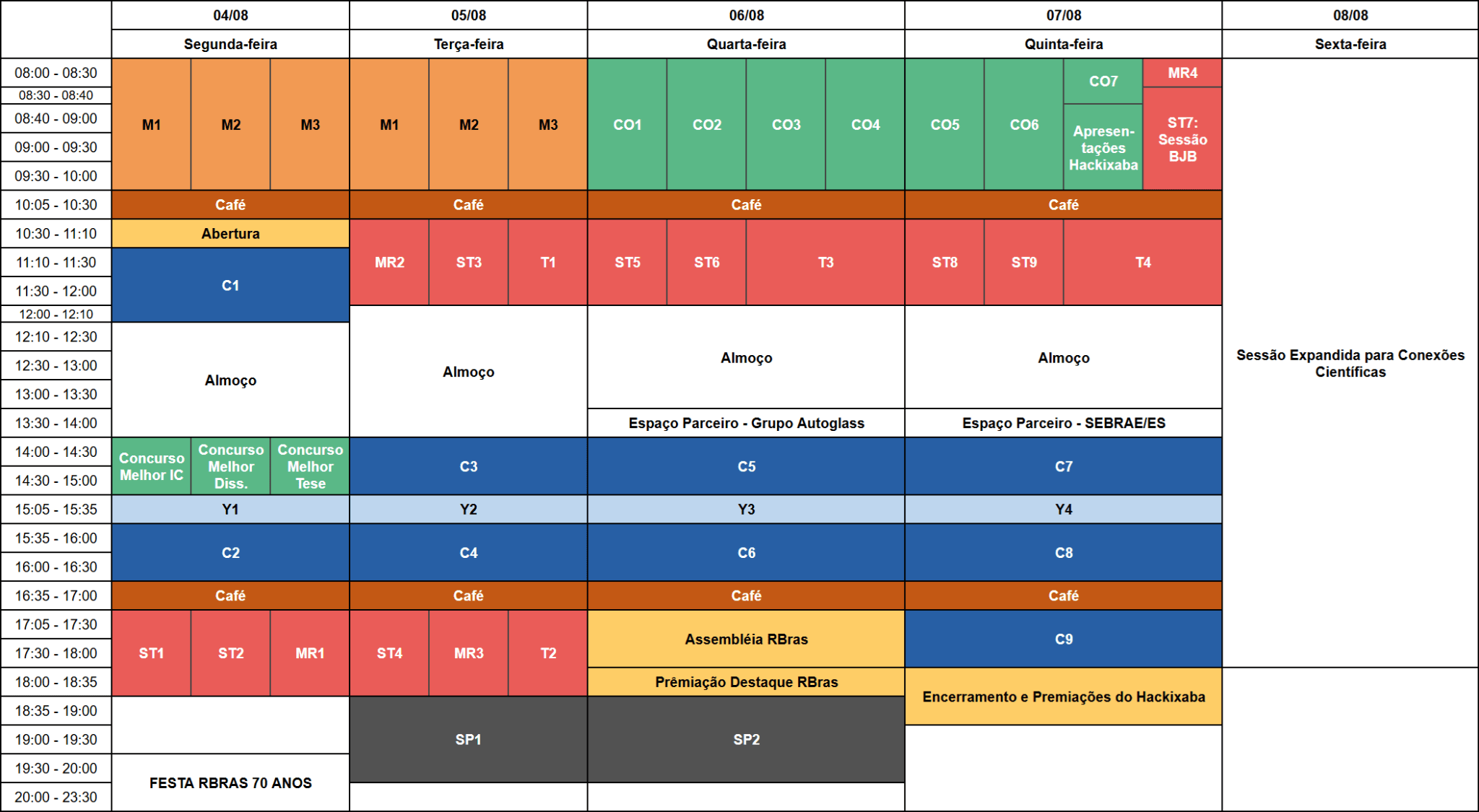
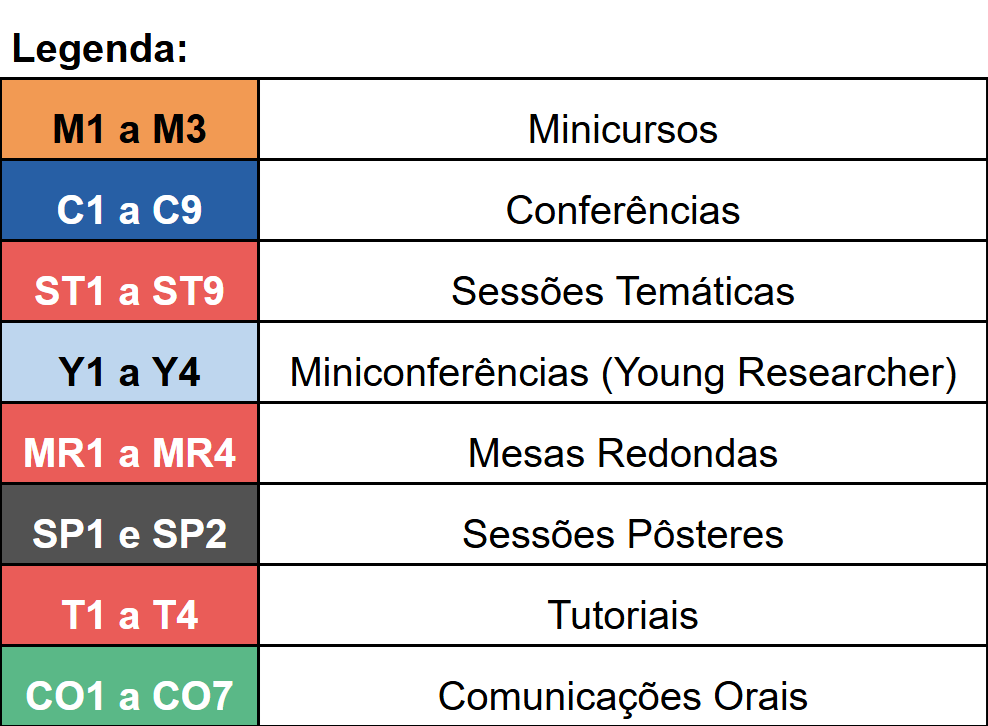
Programação detalhada
- Segunda-feira, 04/08
- Terça-feira, 05/08
- Quarta-feira, 06/08
- Quinta-feira, 07/08
- Sexta-feira, 08/08
Segunda-feira, 04/08
- 12:10 - 14:00
Almoço
Terça-feira, 05/08
- 12:00 - 13:30
Almoço
Quarta-feira, 06/08
- 12:00 - 13:30
Almoço
Quinta-feira, 07/08
- 12:00 - 13:30
Almoço
Sexta-feira, 08/08
Programação resumida